For the demo scroll to the bottom of this article and click on the screenshot.
Clustering is considered to be one of the simpler techniques in machine learning, and often discussion is centered around one algorithm only – K-means, because it’s straightforward and is easy to implement. However digging deeper we can find an amazing amalgamation of surprisingly different algorithms, for instance, look at the content of Clustering by Rui Xu and Don Wunsch . Moreover one of the harder to understand concepts in Bayesian learning – Dirichlet process also has direct connection to clustering.
The main goal of this post is to demonstrate various clustering techniques in action. The program implements 5 different algorithms. The first one is K-means++, which is the usual K-means but with a specific way to choose the initial centroids, for details please refer to the original paper k-means++: The Advantages of Careful Seeding. Since K-means does not really understand the model behind the data, the resulting clusters are often poor.
The next two algorithms – Block Gibbs and Collapsed Gibbs are both dealing with Gaussian Mixture Models (GMMs). GMM is a generative model (as many other Bayesian models), this means that the model actually generates the data at random according to a provided set of parameters. GMM is also a hierarchical model, which means that the data generation occurs in consecutive steps, and the data generated in the previous step is used as the input parameters for the current step. At a high level this works as following. At the first step, we are given the desired number of clusters and a set of hyper parameters, then for each cluster we sample the cluster center, its covariance matrix, and the number of points in that cluster from some given distributions parameterized with the hyper parameters (which are the parameters supplied by the user). Then, at the second step, the actual data points for each individual cluster are generated using Gaussian distributions parameterized with the parameters that we have sampled in the first step. As mentioned above, the number of the points per cluster was also sampled at the first step. Suppose now that we forget which point was generated for which cluster. The inference problem for GMM consists of inferring (reconstructing) point-cluster relationships. Gibbs sampling is one of the methods to attack this inference problem.
To give an intuition behind the Gibbs sampling, imagine a small Markov chain with a few states (no absorbing states, no cycles, etc.). Suppose we run our Markov chain for a long time and decide to stop and record the final state. If we repeat this procedure for a number of times we end up with the (steady-state) distribution over the states. If a state is well-connected, it’s more likely to be the final state of a run and hence it will have a higher probability in the steady-state distribution. Now, if we are given only the steady-state distribution and the Markov chain is concealed from us, we still can say which states are well connected just by looking at the steady-state distribution.
So what does it have to do with Gibbs sampling? Ultimately we want to construct a Markov chain over the parameters of a GMM such that a “well-connected” state corresponds to a set of parameters that fit the model well. So if we run our Markov chain for a long enough time, we, with high probability, end up in a state that fits the model reasonably well. More precisely, suppose that our state is described by the following – values for the cluster centers, covariance matrices for these clusters and, for each data point, a parameter that indicates to which cluster this point belongs. Note that we no longer have a finite state space, in fact, the state space is uncountable because, for example, the cluster centers are real-valued. Having defined the state space we need to specify two remaining ingredients – transitions and their probabilities. In vanilla Gibbs, in the current state, we choose one parameter we want to update and then probabilistically pick its new value so that we would get a better fit. Now when we constructed the new state, we want to know what is the probability to transition to this new state. We derive it by comparing the likelihoods of the current state and the new state (likelihood measures how well parameters fit the model).
While the Gibbs sampling procedure may sound complicated, in application to clustering it’s actually quite straightforward. Suppose, for instance, that a data point has changed its cluster, likely because the new cluster is a better fit for the point than the old one was. This affects both the old and the new clusters. Removal of the point affects the center and the covariance matrix of the old cluster, and when they are sampled in their turn, they are likely to be a better fit for the remaining points. Similarly, adding a point would cause the new cluster’s center and covariance matrix to be adjusted (when they are sampled the next time), and if the added point is actually truly belongs to this cluster in the data set (which may well be given that the new cluster is the best fit among all other clusters) then its would cause the cluster parameters to move in the direction of their true values. This process repeats many times over and after a number of iterations the true cluster parameters and point assignments would emerge.
We actually don’t use vanilla Gibbs in the demo. As mentioned above we use:
- Block Gibbs. The difference with the vanilla is that we sample a few parameters at the same time instead of just one. So each transition actually changes values of a few parameters. The rest is the same. In our program we sample the point cluster assignments all at once, the cluster centers all at once, and the covariance matrices also at once. (We also need to sample the number of points per clusters, but that’s a technicality.)
- Collapsed Gibbs. It is not necessary to to subject all parameters to sampling – given the current allocation of points to the clusters, the distributions for the means and covariance matrices can be inferred. So instead of sampling these parameters we can just use the distributions. Theoretically, we also should get faster convergence because of Rao-Blackwelization, but I haven’t done the measurements.
In the algorithms we considered so far we assumed that the user either knows or is able to provide a good estimate of the number of clusters. What if we don’t want to make a guess on the number of clusters but instead let an algorithm to figure it out? This is what “GMM – Infinite Mixture” option is here for. Another, more formal, name for the algorithm is DPMM – Dirichlet Process Mixture Model. For introduction to the topic of infinite mixtures, I recommend an excellent post by Edwin Chen Infinite Mixture Models with Nonparametric Bayes and the Dirichlet Process. GMMs and DPMMs details can be found in Machine Learning: A Probabilistic Perspective by Kevin Murphy – the most comprehensive book on the subject of Bayesian Machine Learning. For implementation nuances the following reference was very helpful: Gibbs sampling for fitting finite and infinite Gaussian mixture models by Herman Kamper.
At a high level the algorithm works as follows. Initially, the algorithm assumes that all data points belong to a single cluster, and then it fits a Gaussian distribution to this cluster. After that the algorithm iterates over the points, and for each point it decides whether the points stays in the cluster or forms its own, new cluster. The decision is probabilistic, with probability depending on how likely the point was generated by the Gaussian distribution fitted to the cluster. So, the points that are closer to the center are less likely to form a new cluster compared to the points on the fringe. If a point is chosen to form a cluster all subsequent points have a chance to join this new cluster (in addition to an opportunity to start their own). We essentially have two factors to consider: 1) how well a point fits the distribution of the current cluster and 2) the size of the cluster. Smaller cluster have less chance to attract new points compared to the bigger ones – this is a property of the algorithm. So a point has to be a very good fit for a small cluster for it to split from a bigger one. Over many iterations a set of bigger clusters emerges. The one-point clusters continue to appear, but they have little chance of surviving for long because the bigger clusters fit data reasonably well. For another explanation I refer to Edwin Chen blog post mentioned above, particularly to the part that deals with Chinese restaurant process.
The last algorithm – LAC (Locally Adaptive Clustering) is based on Subspace Clustering of High Dimensional Data by Carlotta Domeniconi, Dimitris Papadopoulos, Dimitrios Gunopulos, Sheng Ma. Bayesian clustering algorithm are able to find clusters that are sampled from Gaussian distributions which may look like oval shapes stretched in some dimensions way more than in the others. K-Means would have a very hard time finding such clusters. Non-Bayesian approach for finding such clusters is subspace clustering. The main idea is that the algorithm should be able to learn which dimensions are defining (“important”) for a particular cluster, and which are not. For a particular clusters, its point coordinates in the “unimportant” dimensions may be almost anything and have quite a wide spread, while coordinate in the “important” dimensions should be in a fairly tight range. Obviously, we cannot catch oval shaped clusters if they are not aligned with the axis, but still it’s a nice illustration of a wide variety of clustering algorithms.
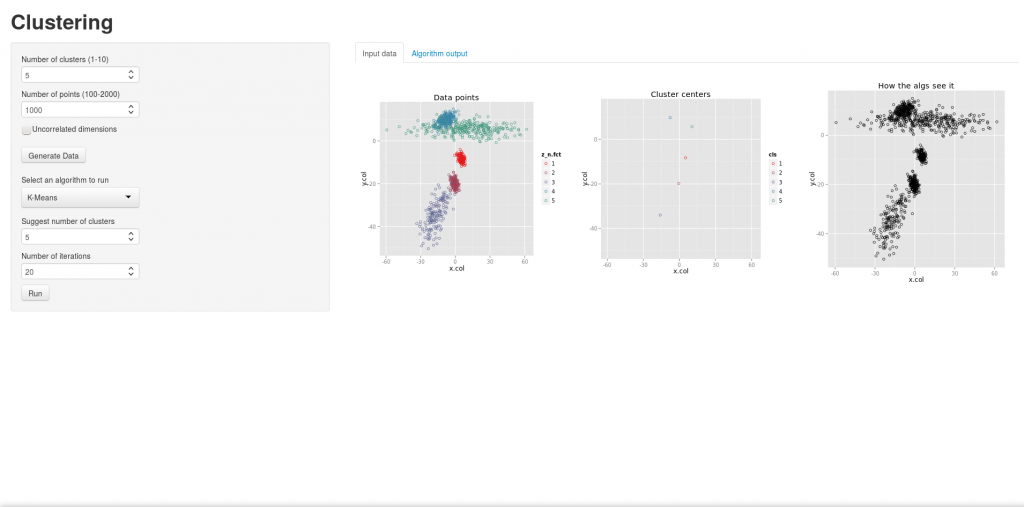
How to use the demo? Click on the image below to load it in a new window. First we need to choose the number of clusters and the combined number of points in all clusters. Choose “Uncorrelated dimensions” if you want the correlation matrices to be diagonal (useful to illustrate the LAC algorithm). Then press “Generate” button. A data set should appear in the “Input data” tab. The first plot shows the clusters, the second shows the cluster centers, and the last one shows just the data points, which is what the algorithms would see.
After we have found an interesting data set, we can choose the algorithm we want to run. All algorithms except for “GMM – Infinite Mixture” have two parameters – “Suggest number of clusters” and “Number of iterations”. “GMM – Infinite Mixture” has only “Number of iterations” parameter, as it will try to infer the number of clusters by itself. Pressing “Run” will start the algorithm and will switch us to the “Algorithm output” tab. All algorithm shows the progress bar at the very top of the page, and in the top right corner the current iteration is displayed. “K-Means” and “LAC” are usually don’t use all the iterations before converging, in which case they would terminate early. The rest of algorithms will run for the specified number of iterations. After run is complete an animation showing the algorithm progress is generated (please allow ~30 sec for it to appear). Press “Play” to see the animation. The left column always shows the actual data (the current clusters on the top and their centers on the bottom), while the right column shows the same for the clusters inferred so far by the running algorithm. The bigger points in the second row indicate the cluster centers with more points.
Implementation notes:
- The entire program except for a tiny piece of Javascript is implement in R. The UI components are written using Shiny. Shiny is an excellent example of Reactive approach, where an update in one component or input can cause a chain reaction of changes to its dependent components. The same approach is employed in many Scala projects as well.
- For Collapsed Gibbs, and Infinite Mixture I have added caching of cluster centers and covariance matrices, so they are not calculated from scratch for every iteration but instead updated only when a data point is being transferred from one cluster to another. This led to 20x speed-up, and actually made the demo plausible.
Source code is here: https://github.com/mikebern/ManyWaysToCluster