Intro
The Microsoft team of Rajbhandari, Rasley, Ruwase, and He introduced a major breakthrough in efficient deep learning training in their seminal “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” paper. By developing the Zero Redundancy Optimizer (ZeRO) and associated techniques, they trained 8x bigger models and 10x better performance over state-of-the-art, as mentioned in the abstract.
The paper groups key innovations into ZeRO-DP (Data Parallelism) and ZeRO-R (Residual) optimizations. ZeRO-DP proposes a staged sharding approach for distributed data parallel training, with each stage building on the last. The stages are:
Stage I – Sharding optimizer states
Stage II – Stage I + Sharding gradient updates
Stage III – Stage II + Sharding model weights
ZeRO-R provides additional lower-level optimizations: activation offloading, GPU memory defragmentation, and tuning communication buffer sizes.
In this post, I will focus on ZeRO-DP, as I believe it represents the most significant contribution of the paper. There are three primary approaches for distributed training: Distributed Data Parallelism (DDP), Tensor Parallelism (TP), and Pipeline Parallelism (PP). As the name indicates, ZeRO-DP is designed as an advancement over vanilla DDP for data parallel training. Therefore, it makes sense to think of basic DDP as Stage 0 when describing ZeRO-DP’s staged optimizations, which then progress from Stage I to III. As DDP, ZeRO-DP is complementary to TP and PP and researchers have been using all three together to train the bigger models.
ZeRO has been implemented by Microsoft in their DeepSpeed library. Meta has also implemented ZeRO first in FairScale and later in PyTorch as a wrapper layer called FSDP. HuggingFace distributed training library Accelerate added integration with ZeRO early on. Google’s TensorFlow also supports techniques similar to ZeRO, which they described in the concurrent paper “Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training” by Y. Hu et al.
Key Insights
Since its release in late 2019, ZeRO has been a topic of numerous blogs delving into its techniques. But I want to share two simple yet subtle observations that really made ZeRO click for me. Let’s walk through them, then see how everything falls neatly into place.
Observation 1: Gradients vs Weight Updates
Gradients and weight updates are often used interchangeably, but they are two distinct concepts. Weight updates refer to the final values used to modify model parameters, which are calculated using gradients, optimizer parameters (such as SGD momentum or Adam states), and hyperparameters like the learning rate. While this distinction is self-evident to practitioners, it’s common to use the term “gradients” loosely. However, understanding the difference between gradients and weight updates is crucial for comprehending the ZeRO technique.
Before stating the second observation we need a brief reminder about collective communication operations often used in distributed traning:
- All-reduce is a collective operation in a distributed system that takes a set of values distributed across multiple processes, performs a specified reduction operation (such as, for example, sum) on these values, and then distributes the result of this operation back to all processes, such that each process ends up with the same final value. In the context of deep learning, where tensors are the primary data structures, the all-reduce operation is applied independently to each corresponding element within a tensor, without interaction between elements at different positions.
- Reduce-scatter is a collective operation that given an input tensor from each process, performs element-wise reduction across these tensors, in such a way that each process ends up with a distinct slice of the resulting tensor.
The name reduce-scatter reflects a naive way to implement this operation where one node is designated as the root and all other nodes send their data to this root node. The root performs element-wise reduction, shards the resulting tensor into slices (one per process) and sends out (scatters) these slices to all other processes keeping one for itself. - All-gather is a collective communication operation where each process in a distributed system contributes its own data slice and collects the concatenated slices from all other processes, resulting in each process having a complete set comprising the whole tensor.
The “all” part in all-reduce and all-gather conveys that all processes ends up with the same exact copy of data.
For efficiency reasons, all-reduce is implemented as reduce-scatter followed by all-gather. This holds for network topologies commonly used in training, like Nvidia NVLink/NVSwitch and Google 3D-torus TPU clusters. Viewing all-reduce as a sequence of two operations rather than one atomic operation unlocks optimizations by letting us insert additional steps in-between reduce-scatter and all-gather and as a result make all-gather act on the modified input tensors, compared to the case when all-gather executes right after reduce-scatter.
A good resource to understand relationship between all-reduce, reduce-scatter and all-gather and implementation details can be found here:
Bringing HPC Techniques to Deep Learning
Stages I and II
Let’s compare vanilla DDP, Stage I, and Stage II. For simplicity, I’m omitting an optimization that allows running the backward pass and gradient synchronization in parallel to enable computation/communication overlap.
| DDP | Stage I | Stage II |
|---|---|---|
| 0. Shard model weights and their corresponding optimizer states. Do this once before the training run starts. | 0. Shard model weights and their corresponding optimizer states. Do this once before the training run starts | |
| 1. Run forward and backward passes | 1. Run forward and backward passes | 1. Run forward and backward passes |
| 2. Reduce-scatter gradients | 2. Reduce-scatter gradients | 2. Reduce-scatter gradients |
| 3. All-gather gradients | 3. On each shard, compute weight updates for weights assigned to this shard only. The preceding reduce-scatter op gives us the necessary gradients and the process already keeps its share of the sharded optimizer states. | 3. On each shard, compute weight updates for weights assigned to this shard only. The preceding reduce-scatter op gives us the necessary gradients and the process already keeps its share of the sharded optimizer states. |
| 4. Compute weight updates using gradients and optimizer states | 4. All-gather model weight updates | 4. Apply the sharded weight updates to the weights assigned to this shard |
| 5. Apply weight updates to all model weights | 5. Apply weight updates to all model weights | 5. All-gather all model weights |
| 6. Go to 1. | 6. Go to 1. | 6. Go to 1. |
As mentioned in the second observation, steps 2 and 3 in DDP correspond to the all-reduce operation. The corresponding operations for Stages I and II are highlighted in bold in the table above.
As you can see, the communication volume is the same across all three cases. This is because the total number of gradients and weight updates to synchronize is equal to the number of weights in the model. This holds true even in the case of mixed precision training because all exchanged values – gradients, weight updates, and the FP16 copies of the FP32 weights – take up 16 bytes. The main benefit comes from memory reduction. Compared to DDP, Stage I shards the optimizer states, while Stage II shards both the optimizer states and gradients.
Stage III
In stage three, we take a step further by also sharding the model weights. Referring to the table above, in step 5 of Stage II, we perform an ‘All-gather: All model weights’ operation. However, instead of gathering all the weights at once, we can make the all-gather operation to run lazily. This means that we load the weights only when they are about to be used, and we do this for each layer separately. In other words, we collect the weights only when we are about to run a forward or backward pass on a particular layer, and we release the weights immediately after.
The forward pass is straightforward:
- Shard the weights and their corresponding optimizer states. Do this once before the training run starts.
- For each layer in forward pass:
- All-gather the layer weights from all shards
- Run the forward pass
- Release the weights that came from the other shards
The backward pass is slightly more complicated, but essentially, it is just Stage II with on-demand loading of the weights:
- Use the previously created shards for weights and their corresponding optimizer states.
- For each layer in backward pass:
- All-gather the layer weights from all shards
- Run the backward pass
- Reduce-scatter the layer gradients
- On each shard, compute the weight updates for the layer weights belonging to that shard
- Apply the computed weight updates to the layer weights belonging to that shard
- Release the weights that came from the other shards
Surprisingly, Stage III does not require significantly more communication compared to DDP, Stage I, and Stage II. The increase in communication volume comes only from the need to collect weights for running the backward pass. The communication volume for collecting weights for the forward pass remains the same across all stages, with the only difference being that in Stage III, this is done gradually on a layer-by-layer basis. This gradual approach presents an opportunity for optimization, where the weights of a layer are collected just before they are needed for either the forward or backward pass.
Specifically, assuming that for DDP and Stages I and II, the total communication volume is 2P, with P representing the volume for each of reduce-scatter and all-gather operations. In Stage III, the communication volume becomes 3P, where the additional P arises from the need to all-gather weights for the backward pass. In exchange for this 50% increase in communication, Stage III offers a significant decrease in memory consumption.
Analysis of Memory Reduction
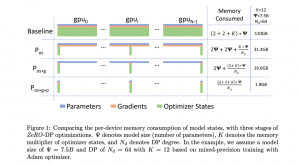
Figure 1 from the paper offers the clearest depiction of memory usage across the different stages. In comparison to the baseline (DDP), sharding the optimizer states results in a significant decrease in memory consumption. In mixed precision training, each of the N-1 shards that don’t have a particular model parameter assigned to them saves 12 bytes per model parameter (K=12 in the figure). This is because Adam momentum and variance each occupy 4 bytes per model parameter, and we also need to store the master copy of the weights in FP32 (which is regarded as part of the optimizer state).
Moving from Stage I to Stage II entails sharding gradients, which saves 2 bytes per model parameter in each non-master shard, as the gradients are computed in FP16. Finally, Stage III further reduces the memory required per parameter by 2 bytes in each non-master shard through sharding the FP16 weights.